2.2 Pinhole Image Formation and linear perspective⧉
Hold a sheet of white paper up in a lit room and look at it. Nothing appears on it — no picture, no scene, just a uniform glow. And yet light from every object in the room is landing on that paper. The trouble is that every point on the sheet receives light from everywhere at once: a single spot gathers rays from the window, the lamp, your face, and the far wall, all summed together. Each point on the paper is the average of all the rays in the room, and averaging everything together leaves only a flat, featureless gray (Figure 2.2.2).
So to make a picture we have to do the opposite of averaging. We must arrange for each point on the sensor to collect light from just one direction — to tie each pixel to one part of the scene. This chapter is about how that selection is done with the crudest possible device, a pinhole, and about the geometry the selection imposes. We will see how a 3D scene flattens into a 2D image by perspective projection (the divide-by-depth that makes distant things small); how that projection becomes a tidy matrix multiply in homogeneous coordinates; what a real camera's intrinsics and extrinsics add, and why cropping a photo is the same as zooming; exactly what perspective preserves (lines and incidence) and what it destroys (angles, lengths, parallelism — hence vanishing points); how a photographer uses focal length to frame and to control the look of the background; and finally how, given depth, we can run the projection backwards and recover 3D points.

2.2.1 Pinhole imaging and the perspective projection⧉
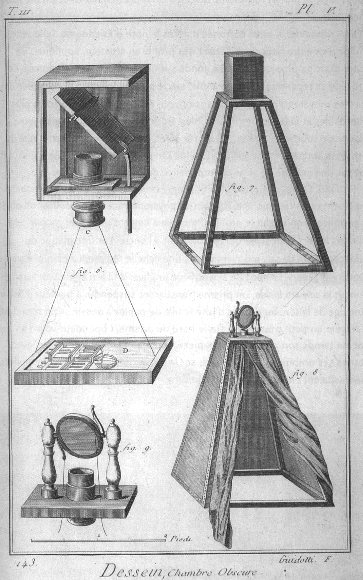
The simplest fix is a wall with a hole in it. Put a barrier between the scene and the paper and punch a tiny hole — a pinhole — and almost every ray is blocked. For each point on the paper exactly one ray survives: the single ray from the scene that happens to pass straight through the hole. That one-ray-per-point rule is precisely the selection we needed, and an image appears — an inverted one (Figure 2.2.2b). This is the camera obscura (Latin for "dark room"), known to Mozi in ancient China and to Aristotle, used by Renaissance painters as a drawing aid, and still the cleanest way to understand every camera built since (Figures 2 and 3). You can make one yourself: a darkened room with a small hole in the window shade projects the street outside, upside down, onto the opposite wall. It is worth doing once — the effect is uncanny, and it makes the geometry below concrete.


The geometry of a pinhole. To make the picture precise, place the pinhole at the origin and point the camera down the $z$ axis, into the scene — our standing convention (Conventions, Notation & Style#Geometry & coordinate systems: $x$ right, $y$ down, $z$ forward). A scene point sits at world coordinates $(X, Y, Z)$; its one surviving ray runs straight to the pinhole and continues on to strike the sensor. Because the physical sensor sits behind the pinhole, the image it forms is inverted — upside down and flipped left-to-right, exactly as on the wall of the dark room. That inversion is a nuisance to reason about, so throughout the book we use a trick: imagine a virtual image plane the same distance in front of the pinhole. No light actually lands there — it is not physical — but it carries the identical image right-side up, so we never have to mentally flip anything (Figure 2.2.5).
The distance from the pinhole to the image plane is the focal length $f$, and it controls how much of the scene fits in the frame. A short focal length puts the image plane close to the pinhole, so a wide swath of the scene projects onto a sensor of given size — a wide-angle view. A long focal length pushes the plane far away, magnifying a narrow slice — a telephoto view. The exact relation between focal length and the field of view (FOV), for a sensor of a given size, is
which just says: the wider the sensor or the shorter the focal length, the more of the world you take in. (Pinholes are not merely a teaching device — several animal eyes, such as the nautilus's, are essentially pinhole cameras, trading sharpness for the simplicity of needing no lens; the eye's full evolutionary path appears in the Bonus chapter.)

The perspective projection equation. Now read off where a scene point lands. In the side view of Figure 2.2.5, the ray from $(X, Y, Z)$ to the pinhole and the image plane at distance $f$ form two similar triangles. The large triangle has height $Y$ and base $Z$ — the point's height and depth — and the small one has height $y'$, the image coordinate, and base $f$. Similar triangles share their ratio of height to base, so $y'/f = Y/Z$, and the same holds horizontally. The image coordinates of the point are therefore
Read it back in words: to find where a point appears, take its world coordinate, divide by its depth $Z$, and multiply by the focal length. That single division by $Z$ is the heart of linear perspective. It is why distant things look smaller — double the depth, halve the image size — why railroad tracks appear to converge, and why a photograph carries a sense of depth that a flat scan of a document does not. Almost everything else in this chapter's geometry is a consequence of dividing by $Z$. The "linear" in linear perspective, by the way, is the painter's term for the rule that straight lines in the world stay straight in the picture — the one nice property the projection keeps, which we make precise two sections from now.


2.2.2 Homogeneous coordinates⧉
The projection equation is doing something slightly awkward. Multiplying by $f$ is a clean linear operation — a matrix could do it — but the division by $Z$ is not linear, and it makes the projection annoying to compose with the other operations we care about: moving the camera, rotating it, translating the scene. We would like the whole pipeline to be matrix multiplications, because then we can chain and invert them with the linear algebra you already know.
The standard fix is homogeneous coordinates. Write a 2D image point not as $(x, y)$ but as a triple $(x, y, 1)$, and agree that any nonzero scaling of that triple denotes the same point: $(x, y, 1)$, $(2x, 2y, 2)$, and $(wx, wy, w)$ all stand for the same 2D point, recovered by dividing through by the last coordinate. The payoff is that the messy division by $Z$ becomes part of this "divide by the last coordinate" convention, so projection turns into an ordinary matrix multiply followed by the standard homogeneous normalization. As a bonus, translation — which is not a linear operation on ordinary $(x, y)$ coordinates — also becomes a matrix multiply in homogeneous coordinates, which is exactly why all of computer graphics and vision lives in them. We keep the machinery light here; the appendix has the details.
The rule that $(wx, wy, w)$ all mean the same point is precisely what lets perspective's divide-by-depth hide inside a linear framework: the projection produces a homogeneous triple, and the final divide-through is the division by $Z$. You never lose information by working up to scale — you recover the actual point whenever you need it by normalizing the last coordinate to 1.
One elegant fact falls straight out of homogeneous coordinates, and it is worth seeing once because it recurs whenever we fit lines or vanishing points. A line $ax + by + c = 0$ is represented by its triple of coefficients $(a, b, c)$, also up to scale, since scaling the equation does not change the line. So a point is a triple and a line is a triple, and a point lies on a line exactly when their dot product is zero: $(a, b, c)\cdot(x, y, 1) = ax + by + c = 0$. This equation is perfectly symmetric in the point and the line. The consequence is the point↔line duality: two points determine the line through them, and two lines determine their intersection point, by the same cross-product formula (Figure 2.2.8). Anything true of points and lines is true of lines and points. We will quietly lean on this when we compute where parallel lines meet.

2.2.3 Intrinsics, extrinsics, and what cropping really does⧉
So far we have quietly assumed the camera sits at the world origin looking down $+z$, the image is centered at $(0,0)$, and one world unit equals one pixel. Real cameras violate all three, and untangling them is the job of the camera matrix. The clean way to think about it — and the way that makes "cropping is zooming" obvious — is to decompose the projection into two stages.
First, reason in normalized image coordinates: project the 3D point straight onto the plane at $z = 1$, with the camera at the origin. This is the bare $x = X/Z$, $y = Y/Z$ — pure geometry, with no mention of pixels, sensor size, or focal length. It is the same for every camera.
Second, map those normalized coordinates to actual pixels with a small affine transformation: scale by the focal lengths $f_x, f_y$ (in pixels, possibly different per axis) and shift by the principal point — the pixel location of the image center, which is arbitrary and rarely exactly the middle of the sensor. Stacking these gives the intrinsic matrix $K$. The full projection is then
read right to left: $[R \mid t]$ are the extrinsics, a rotation $R$ and translation $t$ that move the world into the camera's frame (where the camera is, which way it points); the projection at $z=1$ collapses 3D to 2D; and $K$ converts to pixels. Intrinsics are the properties of the camera-and-lens that do not change as you move around — they change only when you zoom or crop; extrinsics are exactly the parameters that change when you move the camera (Figure 2.2.9).
Where the intrinsics live inside the camera, the extrinsics describe its pose in the world: a rigid 6-DOF transform that carries world coordinates into camera coordinates before any projection happens. The rotation $R$ is a $3\times 3$ orthogonal matrix carrying the three degrees of freedom of orientation (which way the camera points and how it is rolled), and the translation $t$ carries the three of position (where it sits). "Moving the camera" is nothing more than changing $R$ and $t$. This is also the machinery that multiple-view geometry rests on: relating two cameras means composing their extrinsics, and the special case of a camera that only rotates — a tripod panning to shoot a panorama, with no translation between shots — collapses $[R \mid t]$ into a pure rotation, so the two views are related by a single $3\times 3$ homography rather than by parallax. That is exactly why a panorama can be stitched from a flat sequence of warps and why it carries no depth information; we take it up in Multiple view geometry and in the chapter on panoramas and homographies.

This decomposition pays off at once. Because only the second stage — the pixel mapping — knows about the sensor, cropping an image is identical to using a longer focal length (Figure 2.2.10). When you crop to the center half of a frame, you have not changed how the world projects onto the normalized plane; you have only kept a smaller patch of pixels and rescaled it to fill the output, which is precisely what increasing $f_x, f_y$ does. A "2× crop" and a "2× zoom" produce the same picture (at lower resolution for the crop). This is also the formal basis for the crop factor that relates sensor sizes, which we return to in the sidebar two sections below.

The extrinsic transform comes in two flavors that are inverses of each other: world-to-camera (where does this world point land in the camera's frame?) and camera-to-world (where in the world is the camera?). A second, sneakier ambiguity rides on top: even within one convention, packages disagree about what $t$ means — some store the camera's actual position, its center $C$ in world coordinates, while the projection $[R \mid t]$ above instead wants its rotated negation, $t = -R\,C$. Datasets and libraries also disagree about whether $y$ points up or down and which axis is forward. Mixing any of these silently flips signs or mirrors a reconstruction — one of the most common bugs in 3D vision — so if you import a pose matrix from someone else's code, pin down which direction it maps and what $t$ means before you trust it.
2.2.4 What perspective preserves, and what it destroys⧉
Perspective projection — the divide-by-$Z$ — is a surprisingly destructive operation, and knowing exactly what it keeps and what it loses is the core intuition behind a great deal of the book.
What survives is short: straight lines stay straight (a line in 3D projects to a line in the image), and incidence survives (if a point lay on a line, its image lies on the image of the line). That is essentially all. What is destroyed is more striking: angles and lengths are not preserved. Parallel lines in the world generally do not stay parallel — they converge to a vanishing point. A right angle can project to any angle; a circle can become an ellipse; equal-length fence posts shrink with distance. There is no way to read a true length or a true angle off a single photograph without more information, because the depth that would let you undo the divide-by-$Z$ has been thrown away.
The vanishing point deserves a moment, because it is the most visible signature of perspective. Take a 3D line and march along it toward infinity; its projected image approaches a single fixed point — the vanishing point for that direction. Crucially, every line with the same 3D direction — every member of a family of parallels — marches to the same vanishing point, because in the limit the projection forgets position and keeps only direction. Different directions give different vanishing points; sets of parallel lines lying in a common plane (the ground, say) give vanishing points that all fall on one line, the horizon for that plane (Figure 2.2.11). This is the geometry that painters codified as one-, two-, and three-point perspective, and it is what forced-perspective film tricks exploit — the hobbits-and-Gandalf shots in The Lord of the Rings: place a near object and a far object so they project to plausibly related sizes, and the camera cannot tell they are not the same distance away.

2.2.5 Wide-angle distortion: spheres bulge and faces stretch at the edges⧉
There is a second, subtler distortion hiding in the divide-by-$Z$, and it surprises people because it is not a flaw of any lens. Perspective keeps straight lines straight, but it does not keep solid shapes faithful off-axis. A sphere sitting near the edge of a wide field of view does not image as a circle — it images as an ellipse, stretched radially outward, and the wider the angle the more it bulges. The cause is the flat image plane: a point far off-axis is reached by a ray at a large angle, and projecting that oblique cone onto a flat sensor stretches its footprint. The effect grows with field angle, so it is invisible in a telephoto frame and conspicuous at the edges of a wide-angle one. The everyday giveaway is faces in a wide-angle group photo: the person at the edge looks widened and lurched toward the corner, even though the lens drew every straight line perfectly straight (Figure 2.2.12).
This stretch is genuinely the projection's doing, not the lens's — and that distinction matters. A fisheye "distorts" by bending straight lines; this wide-angle stretch keeps lines straight and is exactly what rectilinear (perspective) projection must do to place an off-axis solid on a flat plane. So no better lens can remove it; only changing the projection can — re-rendering the wide field with a locally stereographic mapping over faces (which keeps shapes round) while leaving straight background lines alone. That content-aware correction is the subject of Perspective distortion and its correction.

The effect on a face is the famous "big nose" of a close wide-angle portrait, and it is best felt by driving it yourself (Figure 2.2.13).

2.2.6 Photography with focal length: framing, magnification, and compression⧉
The projection equation is also a working photographer's toolbox. Focal length sets the field of view, and choosing it is a creative decision: a wide lens (under about 30 mm on full frame) sweeps in a whole landscape and exaggerates near–far size differences; a standard lens (around 50 mm) roughly matches the framing of human attention; a telephoto (over about 100 mm) isolates a distant subject and flattens the scene.
The most useful — and most misunderstood — consequence concerns the difference between focal length and subject distance. Both change how large your subject appears, but they are not interchangeable, because they treat the background differently. Suppose you want a person's face to fill the same fraction of the frame. You can shoot wide and step close, or shoot long and step back. Either way the face is the same size — but stepping close with a wide lens makes the background recede dramatically and the nose loom, while stepping back with a telephoto pulls the background forward until it looks compressed, stacked up right behind the subject (Figure 2.2.14). Portrait photographers prize long lenses for exactly this flattering compression. The effect is not really "the lens compressing space"; it is the change in viewpoint — your distance to the subject — that sets the relative sizes of near and far, while the focal length merely chooses how much of that view to crop. Same subject size, different distance, different background: that is the lever.
A related point about sensor size belongs here, even if it feels a touch early. A focal length only means a field of view relative to a sensor size: move the same lens to a smaller sensor and the sensor crops the projected image, narrowing the field of view — the "cropping = longer focal length" fact of Figure 2.2.10, now applied to whole sensors. This is why a focal length on a phone or an APS-C body is usually quoted as a full-frame "equivalent," and it is the perspective that small-sensor cameras give for a stated focal length. The sidebar collects the details.
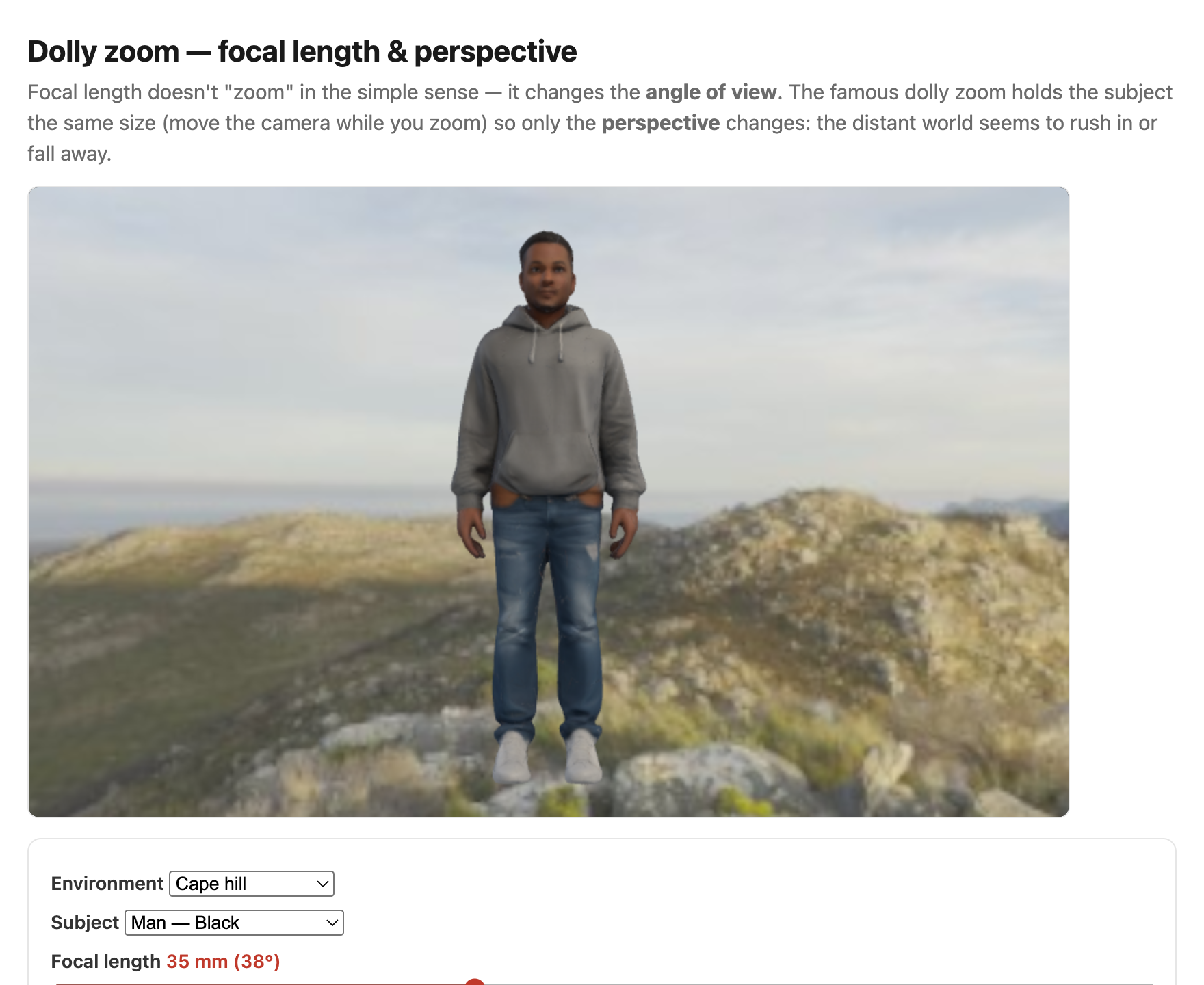
The most vivid demonstration of the lever is the dolly zoom (the "Vertigo" or "trombone" shot): zoom in while dollying the camera back (or out while moving in) so the subject stays exactly the same size while the background visibly rushes in or pulls away behind it. Because only the viewpoint distance is changing, the subject is pinned while the world behind it expands or contracts — the focal-length-vs-distance trade-off, animated (Figure 2.2.15).
Photographers call a $24 \times 36$ mm image frame "35 mm," which sounds like a contradiction. The "35 mm" is the width of the film stock, including the sprocket-hole margins — not the image. Oskar Barnack, designing the first Leica, ran 35 mm cine film sideways through a still camera, giving a 36 mm × 24 mm frame. Today that size is called full frame, and smaller sensors are quoted by their crop factor relative to it: APS-C is about 1.5× — its name comes from the old Advanced Photo System (APS) film format — Micro Four Thirds about 2×, and a phone sensor much smaller still. The crop factor is just the "cropping = longer focal length" fact of Figure 2.2.10 applied to sensor sizes: a 50 mm lens on an APS-C body frames like a 75 mm lens on full frame, because the smaller sensor crops the projected image.
2.2.7 Depth, ray length, and unprojection⧉
One subtlety trips up everyone who works with depth data, so we flag it now. The depth of a scene point is its $Z$ coordinate — its distance along the optical axis, the thing we divided by. It is not the length of the ray from the camera to the point. A point off to the side of the frame has a longer ray than a point dead ahead at the same $Z$, because the ray runs diagonally. Depth sensors, and depth maps generally, report $Z$, not ray length; keeping the two distinct saves a great deal of grief.
With $Z$ in hand, you can invert the projection. The forward map $x' = fX/Z$ loses depth — many 3D points share an image point, namely all the points along one ray. But give the depth back, and a pixel plus a depth determines a unique 3D point. Solving $x' = fX/Z$ for $X$ (and likewise for $Y$) recovers $X = x'Z/f$, $Y = y'Z/f$ — this is unprojection, and it is what a depth camera such as an Intel RealSense does live, turning each pixel-plus-depth into a 3D point cloud (Figure 2.2.16). Such sensors recover $Z$ in several ways — stereo (a later chapter), structured light, or time-of-flight — but once they have it, unprojection is the same simple arithmetic for all of them. This forward-and-back pair — project to lose depth, unproject to restore it given $Z$ — is the bridge from this chapter's one-camera geometry to the multiple-view geometry that measures the missing depth.

With the geometry of a single pinhole in hand — how the world flattens, what survives, and how to run it backwards given depth — we are ready for the device that replaces the pinhole. The next chapter swaps the light-starved hole for a lens, which gathers a wide cone of light and focuses it, buying brightness at the cost of a single plane of focus and a finite depth of field. The projection geometry of this chapter carries over unchanged: a lens, to first order, has exactly the pinhole's perspective.