1.2 How to read this book⧉
This book is organized cross-cuttingly rather than as a tidy linear syllabus. A chapter is sometimes a tool — convolution, the bilateral filter — and sometimes a big idea — priors, the light field. The major themes are designed to recur: you'll meet the same lesson from several angles, in several chapters, and that redundancy is on purpose. Cross-references thread the pieces together, and the repetition is how the ideas stick.
Hammers and nails. The structure also reflects a deliberate balance between tools and applications — between the hammers (convolution, the bilateral filter, optimization, priors) and the nails they are made for (HDR, panoramas, deblurring, refocusing). A purely tool-first table of contents would teach you machinery with nothing to swing it at; a purely application-first one would keep reinventing the same machinery problem by problem. So instead the book is organized by a combination of the two, alternating between hammers and nails so that each motivates the other: a technique arrives because some application demands it, and an application is tackled once the technique to crack it is in hand.
The pedagogy is intuition first. We lead with the idea and a picture, then bring in the math — and only as much math as you need to actually use the tool. The intended reader is a CS undergraduate: comfortable with programming and basic calculus and linear algebra, but new to imaging. Anything heavier than that lives in the Refreshers appendix, so the main text never stalls on machinery you can look up.
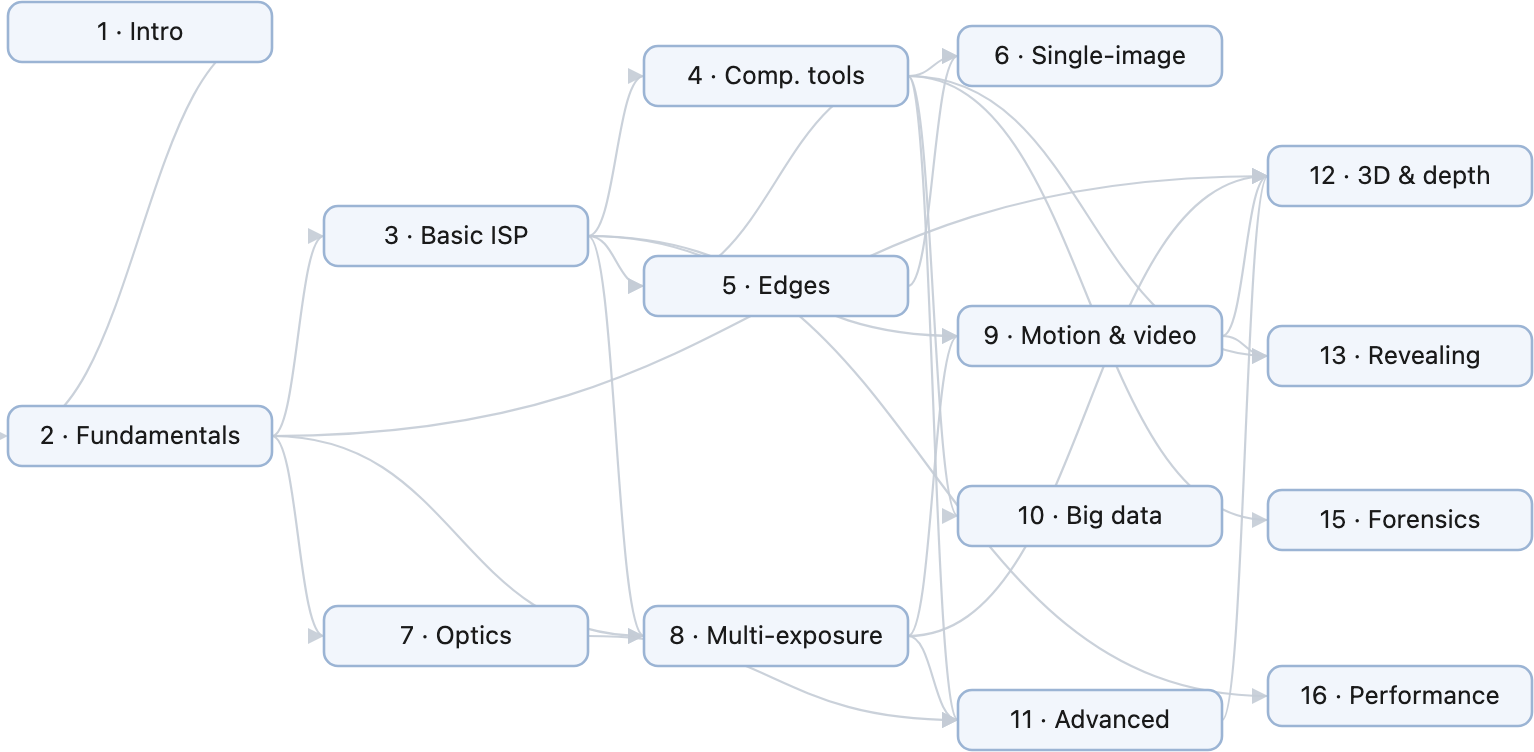
As for a reading order: the FUNDAMENTALS part grounds the physics and perception; BASIC IMAGE PROCESSING gives you the toolkit; later parts build up single-image and then multi-image computational photography. You can read mostly front to back, or follow the dependency graph to chart your own path.
A word on how this book came to be. It grew out of Frédo's computational photography course at MIT — its lectures, slides, and problem sets are the backbone of what follows. It was also written with an AI collaborator (Claude), as a deliberate experiment in AI-assisted authoring: the outline, the figures, the drafts, and even the book's own tooling were co-developed with a model. There is something fitting, and a little meta, about a book that discusses generative AI being partly written by it. The full process — how the outline, figures, and prose are generated, verified, and kept consistent — is documented in an appendix, as a small case study in AI methodology in its own right.
1.2.1 What language for computational photography?⧉
The ideas in this book are language-agnostic, but code has to be written in something, and the book ships in two editions — a Python one and a C++ one. We never show both in the same book; you pick the edition that matches what you're trying to do, because the two languages serve different moments. Python is for thinking and prototyping; C++ is for shipping and running fast. The concepts are identical either way.
The gap between those moments is larger than newcomers expect, and it is widest exactly when you write the low-level code yourself — your own convolution, say, rather than a library call. In Frédo's experience that naive pixel loop runs roughly 1000× faster moving from Python to optimized C++, and you can win at least another ~10× on top of that with Halide. So choosing a language is also choosing a performance regime, which is why the same algorithm can feel either instantaneous or hopeless depending on where you run it; we return to squeezing out those factors in Performance engineering and Halide.
Python is the right default for learning, prototyping, and research. Its great virtue is readability: with NumPy, array code reads almost like the math it implements — out = a + 0.5b does what it looks like it does. It is fast to write and explore, with interactive notebooks and instant feedback, and it sits atop a vast ecosystem (NumPy, SciPy, Pillow and OpenCV, scikit-image, Matplotlib, and the entire deep-learning stack — PyTorch, JAX). Memory is managed for you, and it is the lingua franca of research and machine learning. The catch is speed at the pixel level: a naive per-pixel Python loop is orders of magnitude slower than C, so you must vectorize — push the loop down into NumPy's compiled core — or your code crawls. The global interpreter lock (GIL) limits true CPU threading, packaging and deployment are awkward, dynamic typing lets type bugs hide until run time, and you get little control over memory layout. Still, through NumPy and PyTorch it is fast enough* for most of what we do here.
C++ is the right default for performance and production. It is fast and predictable — close to the metal, with control over memory layout, cache behavior, and single-instruction-multiple-data (SIMD) vectorization — and it is what real camera ISPs, real-time pipelines, and shipped products are actually written in. Static types catch errors at compile time, and it deploys cleanly to phones and embedded hardware. The cost is real: it is verbose and slower to write, manual memory management is a rich source of bugs (out-of-bounds accesses, leaks, use-after-free), the build and toolchain story is heavier, and the edit–compile–run loop is far less interactive than edit–run. Once the algorithm is settled and it has to run fast, on device, at scale, that productivity tax is worth paying.
There's a third option for the hot paths. Halide is a domain-specific language, embedded in C++ and Python, for high-performance image processing. Its central idea is to separate the algorithm — what each pixel computes — from the schedule — how to tile, vectorize, parallelize, and fuse that computation across the memory hierarchy. You get near-hand-tuned speed without hand-writing the tangled, hardware-specific loops, and the same algorithm retargets to CPU, GPU, or DSP by swapping the schedule. It is the basis of real camera stacks. The cost is another language and mental model, best reserved for hot paths you have already identified — premature scheduling is its own trap. We cover it properly in Performance engineering and Halide.
MATLAB deserves a historical note, because much of the computational-photography literature was prototyped in it. For years it was the platform for this kind of work: a strong numerical and linear-algebra library, and an interactive IDE that could read, display, and manipulate images natively — an image was just a matrix, imread/imshow and array slicing made experiments effortless, and the Image Processing Toolbox supplied the rest. It has since been largely displaced by Python — NumPy fills the same array-is-an-image niche, free and open — and especially by PyTorch, whose automatic differentiation and GPU / deep-learning ecosystem MATLAB never matched. We mention it because older papers and code you will meet are written in it, and the array-thinking it taught carries over directly to NumPy.
A note on libraries. This book has you implement the core algorithms from scratch — a bilateral filter, a homography solve, a Poisson blend — because writing one yourself is how you actually understand it (the reference implementations in imageops exist for exactly that). But once a technique is clear and you want to build with it — or dive straight into an advanced project — reach for mature libraries instead of reinventing the plumbing. In Python, the workhorses are Pillow (PIL) for loading, saving, and basic operations, NumPy / SciPy for array math, OpenCV and scikit-image for a large catalogue of vision and image routines, and PyTorch for anything learned (and as a GPU array + autodiff engine even when no network is involved). In C++, the counterparts are OpenCV again (the de-facto standard), Eigen for linear algebra, LibRaw for decoding camera raw, and Halide for the performance-critical pipelines above. The rule of thumb: implement once to learn, then stand on the libraries to go far.
The high-level-bulk-with-machine-code-where-it-counts split this section keeps circling back to is not new; it predates Halide by decades. In 2013 Adobe, through the Computer History Museum, released the source of Photoshop 1.0.1 — about 128,000 lines across 179 files, written for the original Macintosh by Thomas Knoll, the program's sole engineer for version 1 (a computer-vision PhD student whose 1987 image-display hack grew into the app).
The language split is this section's lesson, thirty-five years early: roughly 75% Pascal — the productive high-level language for the bulk of the program — and roughly 15% hand-written 68000 assembly for the speed-critical inner loops. The hot pixels were hand-tuned and the rest left readable: exactly the Python-versus-C++/Halide trade-off, only here a human did by hand what Halide now automates. The code is famously mostly uncommented but well-structured, and it is now read as a cultural artifact — the "Das digitale Bild" project (DFG / LMU Munich) runs an ongoing Critical-Code-Studies effort "reading the source code of Photoshop," treating code as a text to be close-read.
For scale: today's Photoshop is reportedly millions of lines of C++ (Frédo's estimate is on the order of 10 million); Adobe Camera Raw and Lightroom share the same underlying Camera Raw engine, and a typical camera ISP is itself a large proprietary C/C++ codebase — though exact modern sizes are mostly not public. The hand-tuned-inner-loop angle returns in Performance engineering and Halide.
Finally, a note on vibe coding — writing image code with the help of a large language model (LLM). It is now genuinely part of the toolkit: great for boilerplate, file I/O, visualization, and explaining a baffling error, and a quick way to draft a function or a test. But image code is numerically and perceptually subtle, and "looks plausible" is emphatically not "correct." A resampling kernel that is subtly wrong, a color conversion off by a gamma, an antialiasing filter that rings — these produce images that look fine until you check them. So keep the model on a short leash for filtering, resampling, color, and antialiasing, and always verify against a hand-checkable input — a constant, an impulse, a half-plane — before you trust it. And don't assume the failures will be confined to the hard parts: AI coding sometimes fumbles the trivial even when it nails the difficult algorithm above it — see the cross-fade anecdote in the "Vibe coding" chapter. Treat generated image code as guilty until tested (see Developing, Testing and Debugging).